Guide to Insert Data Efficiently in LeanXcale
1. Introduction
When inserting data into a distributed database such as LeanXcale, adherence to specific practices is crucial for optimizing performance. In this guide we will go through a progression from a rudimentary and inefficient method to the most effective approach, highlighting the drawbacks of each method and how subsequent strategies overcome them.
We will use an open dataset with real data from Lending Club Data (Available on kaggle: https://www.kaggle.com/wordsforthewise/lending-club). We have a file, `loans.csv, with a dataset and ingest it several times with different timestamps to reach an appropriate volume for the purpose of this training. The file can be found in the jar in the resources section.
Let us first take a look at the structure of the code and the auxiliary classes.
Each of the approaches, basically, do the table creation, ingest the data,
and clean up the database. Since all approaches have the same structure,
we have a class hierarchy with
an abstract class, Try_abstract, that define the methods that all approaches will have,
and provide also the code that will be reused across approaches,
such as cleaning up the database.
Each approach is presented as a new concrete class inheriting from Try_abstract
with the changes introduced in the new approach.
The first approach is in the class ´Try1_NaiveApproach´.
This first approach makes most of the common pitfalls when ingesting data.
After each approach we identify a problem, and suggest a solution for the problem
that is shown in the next approach, and so on, till we present the optimal way to ingest data.
There are a number of auxiliary classes that are helpful for the purpose of one or more approaches, but are not the focus of this guide, including the class to read the CSV file, a utils class with a variety of methods, or an avl class for an AVL tree used in some of the approaches.
The full code for all approaches and auxiliary code is available at:
2. Naive Approach
Let us look at the code of the naive approach. First, let us look at the structure of each new approach. Basically, it is a class where we will redefine these two methods or only one of them: starting with the create table as can be seen below:
public class Try1_NaiveApproach extends Try_abstract {
public void createTable() throws SQLException {
public void ingestData() {The new class inherits from the abstract class Try_abstract and redefines
the methods createTable and ingestData.
The method createTable states how to create the table, and the ingestData method
has the main loop to ingest all the rows.
When the createTable does not change, we will not repeat it and only show the changes
in the ingestData method.
Here, we will use the following createTable method that will be reused across a
number of approaches:
public void createTable() throws SQLException {
String SQL_CREATE_TABLE_HASH =
"CREATE TABLE " + TABLE_NAME + " (" +
COLS +
"PRIMARY KEY (client_id,loan_id)" +
")" +
" PARTITION BY HASH (client_id)" +
" DISTRIBUTE BY HASH";
utils.createTable(SQL_CREATE_TABLE_HASH);
}As it can be seen the CREATE TABLE defines the columns of the table (COLS is a string with
the definition of all columns in the table) and the primary key.
Additionally, it has PARTITION BY and DISTRIBUTE BY clauses.
For now, we will ignore these clauses and we will talk about them later.
Let us now take a look to the ingestData method that has the main loop ingesting the data:
As it can be seen it creates a reader for the CSV, LoansReader.
The method read will return a row or NULL if the file reach the end.
Problem:
The main problem with this approach is that you run the client application on your laptop and the database server on a remote cloud host.
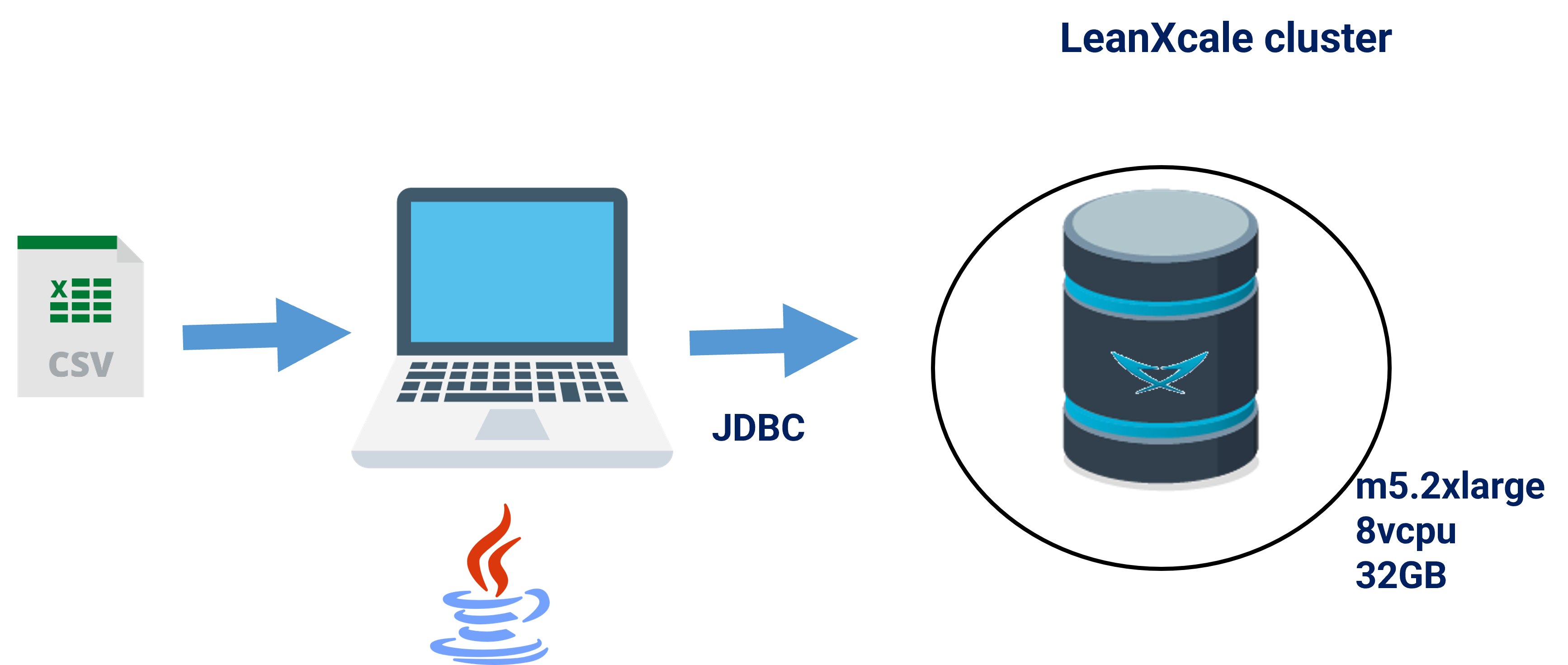
The latency between your laptop and the database server is very high (say 100ms that is around the latency between Madrid and New York), which means that you can insert a row at the frequency allowed by the network latency, i.e. in a second there are 1000ms, each round trip from the laptop to the server takes 200ms, so you can do a maximum of 1000/200=5 round trips per second. This means that even if the insertion is instantaneous, you can only insert at most 5 rows per second.
Solution:
The solution is to run the application in the same data center as the database server.
3. Collocating Application and Database Server in the Same Data Center
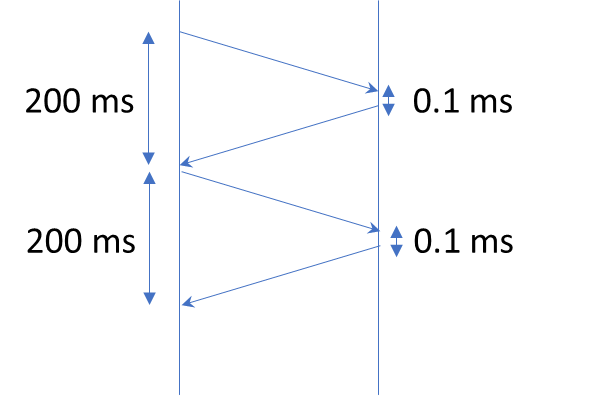
The code remains the same but now we are executing the application close to the database server by running it on a server that is on the same data center as the database server. Now the latency network is very lo (say 0.1 ms). If inserting a row takes 0.1 ms, the round trip from the application to the database server will take 0.1ms+0.1ms=0.2ms so in total each insertion will take 0.3ms, what means that in a second you can do 1000/0.3=3,333 rows per second.
Problem:
The performance is still very low. Why? If we examine what we are doing on each iteration of the loop, we realize we are connecting to the database and disconnecting for each row insertion. The connection to the database is an operation much more expensive than the insertion itself.
Solution:
The solution lies on factoring out the connection to the database out of the loop, so the connection is only performed before inserting and the disconnection is performed when the full data ingestion has completed.
4. Permanent Connection
By establishing the connection once outside the loop, we do not pay the overhead of establishing the connection on every single row insertion. Notice also, that the connection is performed within the parenthesis in the try what means that will be automatically closed when exiting the try block for whatever reason. This is an important good practice that prevents from keeping unused open connections with the database.
public void ingestData() {
try (LoansReader csv = new LoansReader();
Connection connection = utils.connect();
Statement stmt = connection.createStatement())
{
Loan loan;
while ((loan = csv.read()) != null) {
String sql = utils.getInsertSql(loan);
stmt.executeUpdate(sql); //insert the row
connection.commit();
stats.send(1);
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}Problem:
If we examine the code further, we notice that we are executing the SQL statement without first preparing it:
stmt.executeUpdate(sql); //insert the rowWhy is this a problem? Let us first take a look at the work that is done by the execute. First, the SQL statement is compiled and a first query plan is generated as a result. Then the optimizer performs a series of transformations on the initial query plan to get the final query plan. This work is repeated over and over again for every single row insert and is quite expensive compared to a row insert.
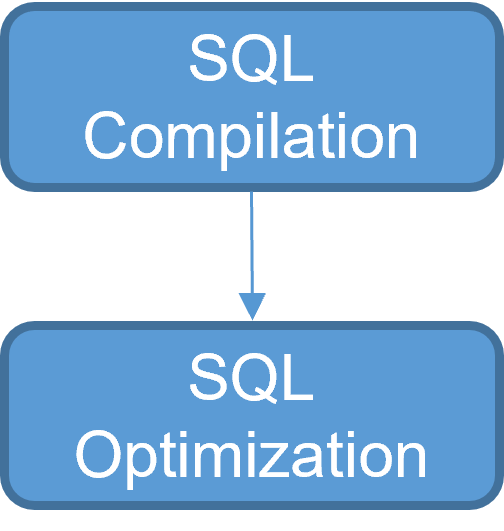
The solution lies in eliminating the compilation and optimization step by preparing the SQL statement before the insert loop.
5. Preparing the SQL statement
Preparing the SQL statement compiles it and caches its query plan on the database server.
So, when we call the execution of the prepare statement, it simply assigns values
to the parameters of the SQL statement and executes the final query plan,
avoiding SQL compilation and query plan optimization.
Here, we can see the new ingestData method that prepares the statement just before
the main loop as part of the try header.
public void ingestData() {
try (LoansReader csv = new LoansReader();
Connection connection = utils.connect();
PreparedStatement prepStmt = connection.prepareStatement(utils.SQL_INSERT_PREPARED))
{
Loan loan;
while ((loan = csv.read()) != null) {
setParams(prepStmt, loan);
prepStmt.executeUpdate();
connection.commit();
stats.send(1);
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}We use an auxiliary method setParams to set the params of each prepared statement:
private void setParams(PreparedStatement prepStmt, Loan loan) throws SQLException {
Object[] args = utils.getParams(loan);
for (int j = 0; j < args.length; j++) {
prepStmt.setObject(j + 1, args[j]);
}
}Problem:
If we take a closer look at the code, we see that for each row insert, we pay the cost of doing a round trip from the application to the database server, that is, invoking the insert, executing the insert at the server, and replying the insert, and so on. Actually the invocation is actually expensive compared to the row insert itself executed at the server. In fact, if we look closely at the cost of the call, we are creating a message that requires us to create the message header (fixed cost) and then serialize the tuple and add it to the message (variable cost).

Solution:
By resorting to batching, we can amortize the fixed cost of each call to the database server among multiple row insertions. Through batching, the fixed cost is paid once for a batch of inserts. So the fixed cost is divided by the number of inserts performed in the batch, thus reducing the overall cost.

6. Batching
Fortunately, this is a common problem, and JDBC provides a way to batch multiple SQL statements into a single call. Here it is the code (we skip the parts that are not changed):
int batchCount = 0;
Loan loan;
while ((loan = csv.read()) != null) {
setParams(prepStmt, loan);
prepStmt.addBatch();
if (++batchCount == BATCH_SIZE) {
prepStmt.executeBatch();
connection.commit();
batchCount = 0;
stats.send(BATCH_SIZE);
}
}
if (batchCount != 0) {
prepStmt.executeBatch();
connection.commit();
stats.send(batchCount);
}For each insert, we do an addBatch. When the number of inserts added to the batch
reaches the BATCH_SIZE, then we execute the batch and commit the transaction,
and then reset the batch counter.
It is important not to forget to commit the transaction, after executing the batch,
since otherwise the changes remain in memory of the query engine and for very large batches
one can run out of memory, or in any case, one it is using memory unnecessarily that could
be used for caching blocks and making for efficient the access for other queries.
Since the number of rows might not be an exact multiple of the batch size,
we check after the loop if there is any outstanding batch and if so, execute it.
Regarding what is the optimal batch size, it mainly depends on the size of each row. A batch size of 1000 is a good starting point. You can from there experiment with larger and smaller sizes to find the optimal point.
Problem:
But wait, is that enough? Not really. Our application has a single thread. This single thread is capable of injecting a load at a certain rate, but if we have a distributed database like LeanXcale, we will not really be able to use its full potential. Each client thread will use at most one storage server that only uses a single core of the database server, so if your database server has more than one core (sum of all cores across all nodes used to run the database), say n cores, you will use at most 1 of n cores. Note that when you send the request to the database server, the database server is completely idle, and the same is true after the database server responds to your request.
Assume that a single transaction (our batch insert) takes 10ms to execute. This means that we can do a maximum of 1000ms/10ms=100 transactions per second, even if the database is capable of doing 1 billion transactions per second.
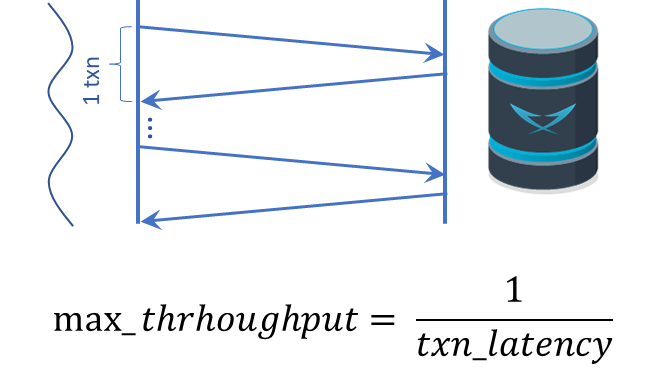
Solution:
The solution lies in the use of multiple threads for the ingestion of the data.
7. Multi threading
The idea is to have a set of threads ingesting in parallel in order to use all the available resources in the server. Each thread will take care of ingesting a fraction of the rows. So how many threads do we need to fully utilize the database server’s resources?
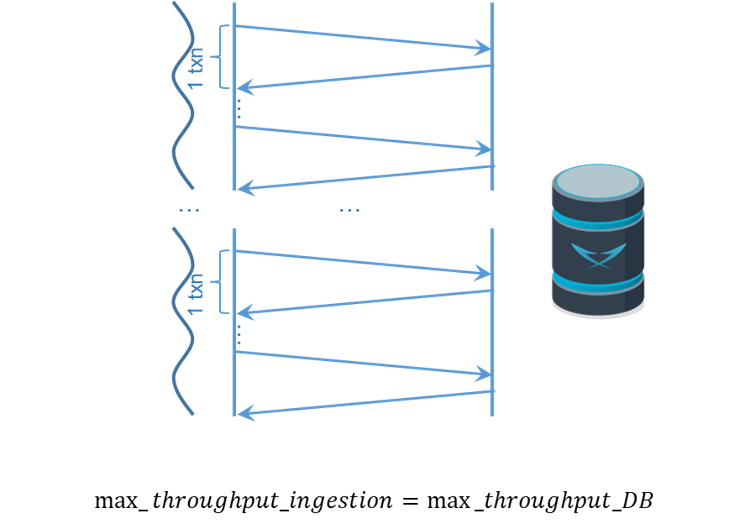
We need at least as many threads as cores used by the database server. However, there might not be outstanding work to be done on the database between requests, so to ensure that the database server always has some work to do, it is recommended to have 2 times as many threads as cores in the database server. This way, all the cores in the database server will always be in use.
One important question is how to share the work among the threads. The idea is that we split the CSV file into as many fragments as threads we have, say n, so it means that we have to find n-1 split points. Since we want fragments of more or less the same size we split the file into chunks of filesize/(n-1). As you might have anticipated, we are not splitting into full lines, this means, that the split point will have to move to the next end of line. In that way, each fragment will have full lines. Note that the CSV has also a header, so we will have to skip it.
Now the ingestData method takes care of creating all the threads and
pass them the assigned to ingest.
public void ingestData() {
try (LoansReader csv = new LoansReader())
{
List<Callable<Object>> task = new ArrayList<>(N_THREADS);
for (int i = 0; i < N_THREADS; i++) {
task.add(Executors.callable(new doIngestData(csv, i)));
}
ExecutorService taskExecutor = Executors.newFixedThreadPool(N_THREADS);
taskExecutor.invokeAll(task);
taskExecutor.shutdown();
} catch (InterruptedException e) {
log.trace("Threaded dataIngest interrupted", e);
}
}The thread class is named doIngestData and its constructor
just store the parameters: the reader object, csv,
and the fragment number of the data to load, indx, into fields of the object:
private class doIngestData implements Runnable {
private final int indx;
private final LoansReader csv;
doIngestData(LoansReader csv, int indx)
{
this.csv = csv;
this.indx = indx;
}The actual main loop ingesting the data is now in the run method of the thread class.
The only change lies in that the read method gets the fragment from which to read
as a parameter (csv.read(section)), so each thread only reads lines
from its assigned fragment (we skip the rest since it remains the same):
public void run() {
try (LoansReader.Section section = csv.createSection(indx, N_THREADS);
Connection connection = utils.connect();
PreparedStatement prepStmt = connection.prepareStatement(utils.SQL_INSERT_PREPARED))
{
//...Problem:
Through a deeper analysis of the behavior of inserting with a large number of rows (i.e., millions), we now observe that the insertion rate decreases over time as the table size increases. Why does this happen? We need to understand how a database works. Data is stored on the leaves of a B+ tree. The database maintains a cache of blocks. When the tree is small, all the blocks fit in memory and access is at memory speed. However, as the tree grows, the cache can no longer hold all the blocks. At some point, the tree becomes so large that scattered accesses to the tree require that a block be flushed from the cache before it can be read, but since the block is dirty (it was previously inserted), it must be written to disk before it can be evicted from the cache. This results in having to perform at least 2 IOs for each row insertion, the one to evict a dirty block and the one to read the new block.
Solution:
LeanXcale provides the ability to automatically split historical tables into fragments with time locality. Thus, each fragment is never too large and is processed at memory speed. If it becomes too big, a new fragment is created. The old fragment gets cold and is kicked out of the cache and the new fragment can use the whole memory of the cache for itself.
8. Autosplit
LeanXcale is not only able to partition data based on the primary key, but also on other dimensions such as time. Typically, historical data is the one that can grow indefinitely, and historical data always has timestamps (or perhaps date plus time columns or an auto-increment column) associated with each row. So by setting auto-split based on the timestamp column, it becomes possible to keep each table fragment small enough to ingest data very efficiently. In this way, the speed of the ingest remains constant regardless of the size of the table, instead of getting slower and slower.
public void createTable() throws SQLException {
String SQL_CREATE_TABLE_HASH_AUTOSPLIT =
"CREATE TABLE " + TABLE_NAME + " (" +
COLS +
"PRIMARY KEY (client_id,loan_id,ts)" + //bidimensional field required as part of PK
")" +
" PARTITION BY HASH (client_id)" +
" PARTITION BY DIMENSION ts EVERY 30000000 KEEP 300000000" +
" DISTRIBUTE BY HASH";
utils.createTable(SQL_CREATE_TABLE_HASH_AUTOSPLIT);
}9. Primary Key Distribution
To distribute by primary key, we need to split the primary keys into as many fragments as we have storage servers (kdvs) in our deployment. Suppose we have 5 storage servers. So we need to split the table into 10 fragments, so we need to find the 4 split points across the 5 fragments. Imagine that the primary keys are the numbers 0 through 49. The fragments we want will be:
-
[0,10]
-
[10,20]
-
[20,30]
-
[30,40]
-
[40,50]
So we need to specify the four split points, which are 10, 20, 30, and 40. The fragments are automatically distributed across all storage servers in a round robin fashion.
How can we do this splitting process for real data? Notice that is important to be able to split the data into fragments of similar size. Another important point is that we do not need to read all data for estimating the ranges of the primary keys for fragments of even size. We can do sampling of the data for what a small percentage suffices. In here we will do with a 1% of the data that is good enough. In order to split the data we need to estimate the split points of fragments of even size. Sampling lies in reading randomly a small fraction of the data, and finding the split points for this small random fraction of the data. Statistically, the split points will be similar to the ones of reading the full data set.
The next issue is how we can write randomly CSV rows? We can certainly seek a position in the CSV file that can be a random number between 0 and the length of the file minus 1. However, it might not correspond to the the beginning of a line. As we did to split the file among several threads, we just need to move to the next end of line. If we reach the end of file then either we move to the previous end of line or search a new random number.
For each of the lines that we read randomly we have to keep the columns of the primary key, in our case, client_id, load_id. For storing all the values read we use an AVL tree so we can keep the read primary keys sorted. After reading the target 1%, we just need to traverse the AVL in order and identify the keys at the split points. Since we want to split into 8 fragments, we need 7 split points, and if the total number of keys stored in the tree are k, the split points are the keys found at positions k/7, 2k/7, 3k/7, …, 6k/7.
If we know that the rows are randomly distributed with respect the key, then we can just read the first 1% of the file. We are assuming that is the case, so we reuse the code we used to split the data across threads. Basically, we define a section of the file out of 100 sections, read it as store the key values in the AVL tree, and then extract the split points as stated before. The resulting code is:
public String getSplitPoints(LoansReader loansReader, int regions) {
//Read a sampling of a random 1% of the file in order to get the split points
log.info("Looking for split points");
AVLTree<LoanAvlKey> avlTree = new AVLTree<>();
// Read 1% of file to estimate split points
try (LoansReader.Section section = loansReader.createSection(0, 100))
{
loansReader.setDuration(0);
Loan loan;
while ((loan = loansReader.read(section)) != null) {
avlTree.insert(new LoanAvlKey(loan.getClientId(), loan.getId())); //build am AVL tree with the data
}
}
// avlTree.printSort();
List<LoanAvlKey> splitKeys = avlTree.getSplitKeys(regions); //get the split points from the balanced tree
StringJoiner splits = new StringJoiner(", ");
for (LoanAvlKey key : splitKeys) {
splits.add("(" + key.getClientId() + ", " + key.getLoanId() + ")");
}
return splits.toString();
}Once we have the split points of the data to be loaded now we can create the table
with the right partitions by using the split points from the sampling.
In LeanXcale one can define the criteria to partition the data, and one can choose
one of those partitioning criteria as distribution criteria.
We already had a partitioning criteria, and we auto partition by the column ts.
We need to add the partitioning by prefix of the primary key, the genuine primary key,
that is client_id and load_id, providing the list of split points previously computed
the clause PARTITION BY KEY AT.
Finally, we have to add the distribute clause, DISTRIBUTE BY KEY, that states to distribute
by the primary key partitioning.
So our final createTable method is:
public void createTable() throws SQLException {
String splitPoints;
try (LoansReader loansReader = new LoansReader())
{
splitPoints = utils.getSplitPoints(loansReader, REGIONS);
}
log.info("Split Points:{}", splitPoints);
String SQL_CREATE_TABLE_PKRANGE_AUTOSPLIT =
"CREATE TABLE " + TABLE_NAME + " (" +
COLS +
"PRIMARY KEY (client_id,loan_id,ts)" + //bidimensional field required as part of PK
")" +
" PARTITION BY KEY (client_id,loan_id) AT " + splitPoints +
" PARTITION BY DIMENSION ts EVERY 30000000 KEEP 300000000" +
" DISTRIBUTE BY KEY";
utils.createTable(SQL_CREATE_TABLE_PKRANGE_AUTOSPLIT);
}